Want a quick win with multimodal AI? In this post, you’ll build a tiny Python app that uses a Llama vision model to look at an image and tell you what it is. We’ll use Ollama to run the model locally (no paid keys required), then call it from Python. By the end, you’ll run the script on your machine and see real descriptions printed to your terminal.
What we’ll build
A command-line tool:
- Input: an image file (JPEG/PNG).
- Output: a short description of what’s in the image, generated by a Llama multimodal model.
- Stack: Python +
ollama(local LLM runtime) + Llama vision model.
Prerequisites
- Python 3.9+ and
pip - Ollama installed (macOS, Windows, or Linux):
- Download and install from the Ollama site, then ensure
ollamaworks in your terminal:ollama --version
- Download and install from the Ollama site, then ensure
- Pull a Llama vision model. As of writing, a good default is:
ollama pull llama3.2-visionIf your Ollama catalog differs, any “vision” or “llava” compatible model works. You can list models withollama list.
Create a Python virtual environment
python -m venv .venv
# Windows
.venv\Scripts\activate
# macOS/Linux
source .venv/bin/activateInstall dependencies:
pip install ollama pillowollamais the official Python client for the local Ollama server.Pillow(PIL) lets us open/validate image files and optionally resize/convert.
The Python app
Create describe_image.py:
import sys
from pathlib import Path
from typing import Optional
from PIL import Image
import ollama # pip install ollama
MODEL_NAME = "llama3.2-vision"
PROMPT_TEMPLATE = """You are an assistant that describes images clearly and concisely.
Return 1–3 sentences describing the main subject and notable details.
Be specific but avoid guessing text that isn’t legible."""
def validate_image(path: Path) -> Optional[Path]:
if not path.exists():
print(f"Error: file not found: {path}")
return None
try:
with Image.open(path) as im:
im.verify() # quick integrity check
return path
except Exception as e:
print(f"Error: not a valid image ({e})")
return None
def describe_image(image_path: Path) -> str:
"""
Sends the image to the local Llama vision model via Ollama and returns the description.
"""
# Ollama accepts an array of messages; attach the image path on the user message.
response = ollama.chat(
model=MODEL_NAME,
messages=[{
"role": "user",
"content": PROMPT_TEMPLATE,
"images": [str(image_path)]
}],
options={
# Tweak generation if you like:
"temperature": 0.2,
"num_predict": 256
}
)
# The assistant's message is in response['message']['content']
return response["message"]["content"].strip()
def main():
if len(sys.argv) < 2:
print("Usage: python describe_image.py <path-to-image>")
sys.exit(1)
image_path = Path(sys.argv[1])
valid = validate_image(image_path)
if not valid:
sys.exit(2)
print(f"Using model: {MODEL_NAME}")
print(f"Analyzing image: {valid}\n")
try:
description = describe_image(valid)
print("Description:\n")
print(description)
except ollama.ResponseError as e:
print(f"Ollama error: {e}")
print("Tip: Make sure the model is pulled and the Ollama service is running.")
sys.exit(3)
except Exception as e:
print(f"Unexpected error: {e}")
sys.exit(4)
if __name__ == "__main__":
main()
What the code does
- Validates the image path and ensures the file is actually an image.
- Sends a message to the Llama vision model via
ollama.chat(), attaching the image in theimagesarray. - Prints the model’s natural-language description.
Run the app
- Start (or ensure) the Ollama service is running. On most systems, Ollama runs as a background service after installation. If needed:
ollama serve(Keep that window open, or run it as a service.) - In another terminal where your virtual environment is active, run:
python describe_image.py ./samples/cat.jpgReplace./samples/cat.jpgwith any local JPG/PNG.
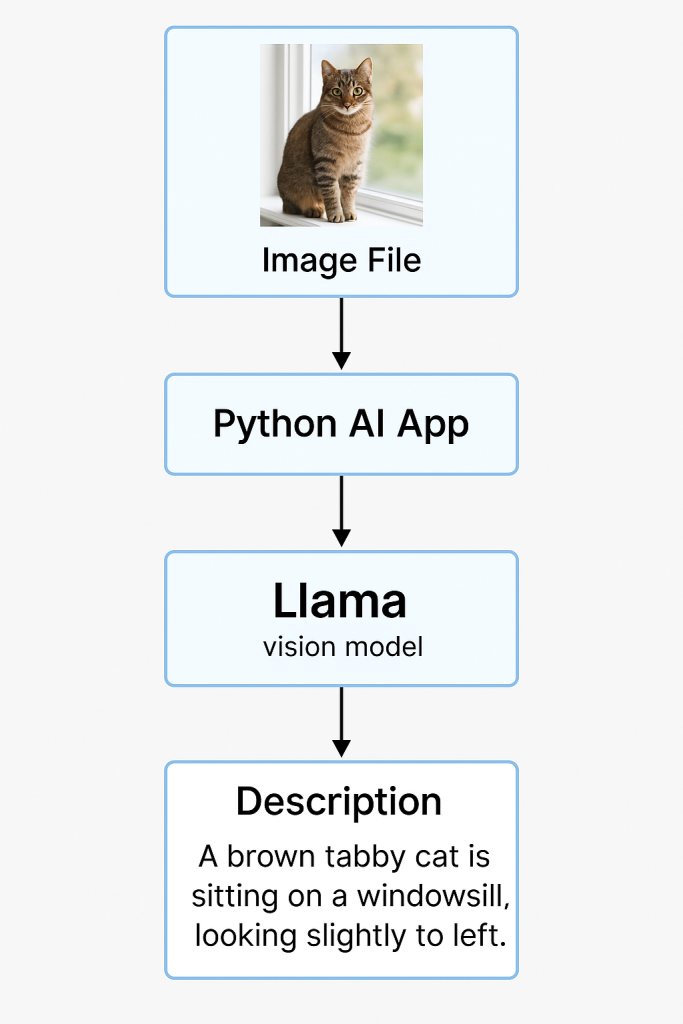
Example output
Using model: llama3.2-vision
Analyzing image: samples/cat.jpg
Description:
A brown tabby cat is sitting on a windowsill, looking slightly to the left.
Sunlight highlights the fur, and a blurred outdoor scene is visible beyond the glass.
Your output will vary; that’s normal. If the response looks too long or too vague, lower
temperatureor tighten the prompt (e.g., “Return a single concise sentence.”).
Troubleshooting
Ollama error: model not found
You likely didn’t pull the model. Run:ollama pull llama3.2-visionConnection refusedor timeouts
Ensure the Ollama server is running:ollama serve(or restart it).
On Windows/macOS, try quitting/relaunching the Ollama app.- Slow first run
The first inference can be slower while weights are paged into memory. Subsequent runs are faster.
Extending the app
- Batch mode: Loop over a folder and describe every image.
- Structured output: Ask the model to return JSON (e.g.,
{ "objects": [...], "scene": "..." }) and parse it. - Confidence: Prompt the model to include uncertainty (e.g., “If unsure, say you’re not certain.”).
Recap
You just built a tiny—but powerful—Python app that uses a local Llama vision model to describe images. With Ollama handling the model runtime and a few lines of Python, you can experiment with multimodal AI entirely on your machine. Try different images, tweak the prompt, and explore richer outputs like object lists or captions tailored for your use case.
Discover more from CPI Consulting
Subscribe to get the latest posts sent to your email.